How a Small Open-Source AI Project Got Discovered Without a Marketing Budget
A few overseas AI creators recently mentioned Memex. One Instagram Reel ended up with around 16,000 likes. The GitHub repo picked up a new wave of stars. It was not a breakout moment, but for a small open-source project with no marketing budget, it was enough to make us stop and ask: where did this come from?
The funny part is that we did not know at first. GitHub traffic only showed vague referral sources. We searched X, TikTok, and YouTube by hand and still could not find the real trigger. Eventually I asked ChatGPT to help look for recent mentions of Memex overseas. It found the posts.
So yes, the growth source of an AI project was discovered by asking an AI. That feels almost too on the nose.
Memex is an open-source, local-first AI journal. You can drop in text, photos, voice notes, and screenshots; AI agents help organize those fragments into timeline cards, Markdown knowledge, and personal insights. But this post is less about product features and more about the path: how a tiny project with no paid distribution slowly became visible.
The starting point was not marketing
The earliest seed was not a landing page, a launch plan, or a clever growth trick. It was our own research into Claude Code and agent workflows.
We had a strong feeling early on: agents do not always need to start with complex databases, vector indexes, or a heavy RAG stack. In many cases, if information is organized as Markdown and the agent can use basic file operations - search, read, write, move, connect - it can already do surprisingly useful work.
That became one of the base intuitions behind Memex. We were not trying to build a traditional journal app. We were trying to build something closer to a file system for personal memory. The user can capture messy fragments. Agents can organize them. Structure can grow over time instead of being forced up front.
When we first put it out there, almost nothing happened. We wrote about the idea. We cleaned up the README. We built the website. We shipped to the App Store and Google Play. We posted a little on Xiaohongshu and Zhihu. We used the app ourselves and fixed the rough edges.
This stage was slow. It is easy to start wondering whether the thing is only interesting to you.
The first cold start came from a comment
Then Andrej Karpathy shared a gist called LLM Wiki. The rough idea is to let an LLM maintain a Markdown-based knowledge base. Instead of doing retrieval only when a question is asked, the model keeps reading, editing, linking, and improving the files so the knowledge base compounds.
That landed very close to how we had been thinking about Memex. We saw the gist and left a serious comment. Not a drive-by link drop. We explained why the idea resonated, how we were applying a related pattern to personal memory, and shared Memex as an example.
That comment became our first real cold start.
The lesson was simple, but it stuck: when you have no resources, the best promotion often does not look like promotion. It looks like showing up in the right conversation with something real to say.
You have to have actually thought about the problem. You have to have built something. Then when the discussion reaches the exact place your project lives, you can contribute instead of advertise.
Built in public is quieter than it sounds
This is what "built in public" means to us. It is not just posting every small changelog and hoping people clap. Most days, nobody will.
It is more like leaving a trail of thinking: what you believe, what changed your mind, what broke, what you learned from users, which technical bets you are making, and which parts still feel uncertain.
Early on, that trail can feel pointless. But it matters when a bigger conversation suddenly overlaps with your work. People can follow the trail backward and see that you did not just appear to harvest attention. You have been living inside the problem.
One hundred stars is small, but not meaningless
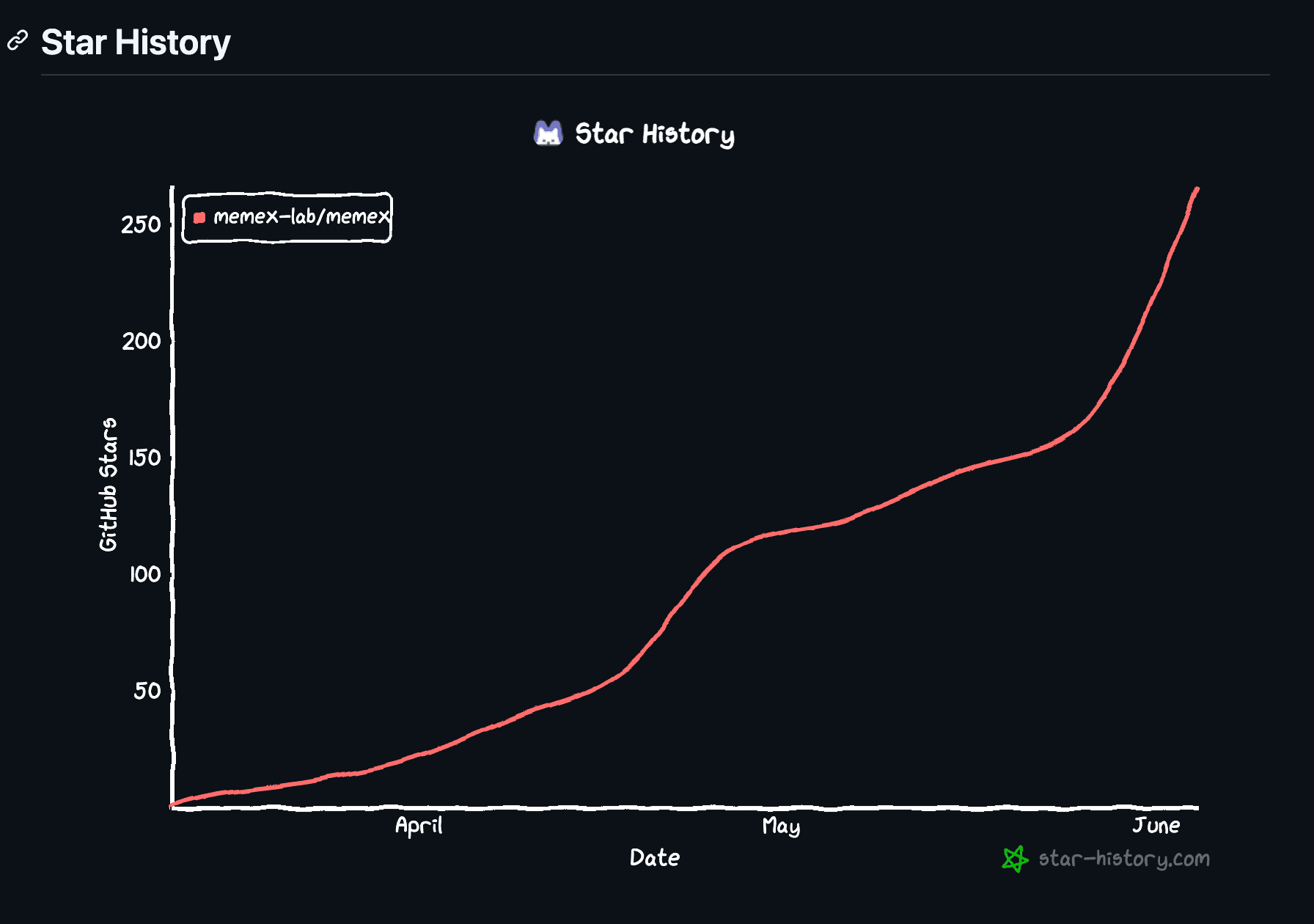
Memex slowly crossed 100 GitHub stars. That is not a big number. But for a small open-source project, it is a signal. It means the project is no longer only interesting to the people building it.
After that, the path became a little less lonely. A few small creators noticed us. Then a few larger accounts shared the project. Eventually one Instagram post brought a much bigger wave of attention than anything we could have planned ourselves.
The path was not magical:
- Think through a problem before it becomes obvious.
- Build a real product around that judgment.
- Write down the thinking, even when almost nobody reads it.
- Join relevant technical conversations with substance.
- Let the first users find you through those traces.
- Keep improving the product after the first small signal.
- Accept that discovery may happen later, and indirectly.
There was no campaign behind it. No paid distribution. No overseas partner. Just a lot of small, boring work: update the README, improve the website, publish the stores, answer feedback, tighten the product, write when we learn something, repeat.
Why this window exists for individual developers
This experience made me more convinced that the current AI agent wave gives individual developers a real opening.
Not because distribution is suddenly easy. It is not. The opening exists because everyone is still renegotiating what the right abstractions are. Agents, memory, local-first data, Markdown, mobile AI, personal workflows - none of this has fully settled.
If you understand a new pattern early enough, build around it, and keep explaining what you are learning, you can be found by people who are also trying to understand that pattern. You do not need to outspend larger teams. You need to be early, concrete, and useful.
The painful part
There is another side to this, and it is less romantic.
Our understanding of agents has changed quickly over the last few months. Once your mental model changes, old product architecture starts to look wrong. Places that felt reasonable before now feel awkward. Some abstractions become too small. Some flows need to be rebuilt.
Memex is preparing for a larger refactor because of that. This is also part of building in public: not only showing the result, but showing how a product gets pushed around by the team's changing understanding.
Where we are now
Memex is still early. There are many things we know are not good enough yet. But the direction feels clearer: local-first personal memory, organized by agents, with source code you can inspect and data you can keep.
If you are interested in AI agents, local-first software, personal memory, journaling, or companion-like tools, the best place to start is the Memex GitHub repo. Issues, ideas, and real usage feedback are all useful at this stage.
The honest takeaway is not that we found a secret growth hack. We did not. The takeaway is smaller and more useful: if you are building something with no resources, make sure your work leaves enough public evidence that the right people can discover it when the right conversation finally happens.
Original materials
Here are the original references behind this English version: